معرفی مدل ترجمه ماشینی نورونی مقاوم از گوگل

امروزه گوگل پیشتاز ترجمه ماشینی در جهان است و همه شاهد هستند که کیفیت ترجمه گوگل چه پیشرفت روزافزونی دارد. ما قبلاً در وبلاگ ترنسنت با انتشار مطالبی با موضوعاتی نظیر دوربین ترجمه گوگل و نحوه ترجمه فایل pdf سعی کردیم ویژگیهای عمومی جدیدتر مترجم گوگل را معرفی کنیم. اما شاید خواندن مطالب تخصصیتر درباره آنچه در پسزمینه ترجمهگر گوگل میگذرد نیز برای مخاطبان خالی از لطف نباشد. با ما با یکی از جدیدترین عنوانهای وبلاگ هوش مصنوعی گوگل با موضوع ترجمه ماشینی نورونی مقاوم همراه باشید. خوشحال میشویم اگر توصیهای درباره بهبود ترجمه و واژهگزینی برای این متن تخصصی کامپیوتر و هوش مصنوعی دارید، آن را در بخش نظرات بیان کنید.
دوشنبه، ۲۹ ژوئیه ۲۰۱۹
ارسال: یونگ چنگ، مهندس نرمافزار، بخش تحقیقات ترجمه گوگل
در سالهای اخیر، ترجمه ماشینی نورونی[1] (NMT) با استفاده از مدلهای ترانسفورمر[2] موفقیت فوقالعادهای داشته است. مدلهای NMT معمولاً بر مبنای شبکههای عمیق نورونی و بهشکلی کاملاً دادهمحور و بدون نیاز به دانستن قوانین دستور زبان برای کار روی مجموعههای موازی عظیم سرتاسری (جفت متنهای ورودی/خروجی) آموزش داده میشوند.
علیرغم این موفقیت عظیم، مدلهای NMT نسبت به تغییرات جزئی ورودی حساس هستند. یک تغییر کوچک در متن ورودی ممکن است باعث بروز خطاهای مختلف (مثل ترجمهی ناقص[3]، ترجمهی پر اِطناب[4]، یا ترجمهی اشتباه[5]) شود. مثلاً، مدل پیشرفتهی ترانسفورمر NMT میتواند جملهی آلمانی زیر را کاملاً صحیح به انگلیسی ترجمه کند:
Der Sprecher des Untersuchungsausschusses hat angekündigt, vor Gericht zu ziehen, falls sich die geladenen Zeugen weiterhin weigern sollten, eine Aussage zu Machen.
ترجمهی ماشینی انگلیسی:
The spokesman of the Committee of Inquiry has announced that if the witnesses summoned continue to refuse to testify, he will be brought to court. [6]
اما اگر یک تغییر کوچک در جمله بهوجود بیاوریم و مثلاً به جای geladenen از کلمهی مترادف آن یعنی vorgeladenen استفاده کنیم، ترجمه آلمانی به انگلیسی بسیار متفاوت (و در این مورد غلط) خواهد بود:
Der Sprecher des Untersuchungsausschusses hat angekündigt, vor Gericht zu ziehen, falls sich die vorgeladenen Zeugen weiterhin weigern sollten, eine Aussage zu machen.
ترجمهی ماشینی انگلیسی:
The investigative committee has announced that he will be brought to justice if the witnesses who have been invited continue to refuse to testify.[7]
مقاوم نبودن مدلهای NMT باعث شده است که بسیاری از نمونههای تجاری را نتوان در فعالیتهای جدی که این سطح از ناپایداری در آنها قبول نیست، بهکار گرفت. به این ترتیب، آموزش مدلهای ترجمه مقاوم به تغییرات ورودی نه تنها اقدامی مطلوب، بلکه در بسیاری از سناریوها ضروری است. البته تعداد پژوهشها در این زمینه اندک است.
ما در «ترجمه ماشینی نورونی مقاوم با ورودیهای هماورد مضاعف[8]» (برای ارائه در رویداد ACL 2019) رویکردی را پیشنهاد میکنیم که از نمونههای هماورد[9] تولیدشده استفاده میکند تا ثبات مدلهای ترجمهی ماشینی را در برابر تغییرات کوچک ورودی بهبود دهد. برای این منظور، به یک مدل NMT مقاوم میآموزیم که مستقیماً نمونههای هماوردی را که با دانشی از مدل و با هدف انحراف پیشبینیهای مدل تولید شدهاند حل کند. در پایان نشان خواهیم داد که این رویکرد عملکرد مدل NMT را در معیارهای استاندارد بهبود میبخشد.
مقدمه ای بر شبکههای مولد تخاصمی (Generative Adversarial Networks)
آموزش مدل با AdvGen
یک مدل NMT ایدهآل برای ورودیهای جداگانه که تفاوت اندکی دارند ترجمههای مشابهی ارائه میکند. ایدهی رویکرد ما گیجکردن مدل ترجمه با ورودیهای هماورد به امید مقاومتر کردن مدل است. برای این منظور، از الگوریتمی به نام تولید هماورد[10] (AdvGen) استفاده میکنیم که نمونههای هماورد احتمالی را برای گیجکردن مدل تولید میکند و سپس آنها را برای آموزش دفاعی دوباره به مدل تغذیه میکند. اگرچه این روش از ایدهی شبکههای مولّد هماورد[11] (GANها) الهام گرفته است، به شبکهی تمیزدهنده متکی نیست و به سادگی نمونههای هماورد را در آموزش اعمال میکند تا مجموعهی آموزشی را تنوع و گسترش دهد.
در گام نخست باید مدل را با استفاده از AdvGen گیج کرد. برای این منظور، در آغاز با استفاده از ترانسفورمر میزان اتلاف ترجمه را بر مبنای یک جملهی ورودی مرجع، یک جملهی ورودی هدف، و یک جملهی خروجی هدف محاسبه میکنیم. سپس، AdvGen بهصورت تصادفی و با یک توزیع یکنواخت چند کلمه از جملهی مرجع را انتخاب میکند. هر کلمه دارای فهرستی از کلمات مشابه است؛ یعنی کلماتی که میتوانند جایگزین هم شوند. الگوریتم AdvGen از این فهرست کلمهای را که بیش از همه احتمال دارد در خروجی ترانسفورمر خطا ایجاد کند انتخاب میکند. جملهای که از این کلمات هماورد تولید شده است دوباره به ترانسفورمر داده میشود تا مرحلهی دفاع آغاز شود.

ابتدا، مدل ترانسفورمر بر یک جملهی ورودی اعمال میشود (پایین، سمت چپ) و سپس، اتلاف ترجمه در ارتباط با جملهی خروجی هدف (بالا، سمت راست) و جملهی ورودی هدف (وسط، سمت راست؛ که با عبارت «<SOS>» آغاز شده) محاسبه میشود. در گام بعدی، تابع AdvGen جملهی مرجع، توزیع انتخاب کلمه، کلمههای انتخابی، و اتلاف ترجمه را بهعنوان ورودی دریافت میکند تا نمونهی هماورد جملهی مرجع را بسازد.
در مرحلهی دفاعی، جملهی هماورد دوباره به مدل ترانسفورمر تغذیه میشود. اتلاف ترجمه مجدداً محاسبه میشود اما این بار جملهی ورودی هماورد مبنای محاسبه قرار میگیرد. الگوریتم AdvGen با استفاده از روش فوق جملهی ورودی هدف، جایگزینی کلمات، توزیع انتخاب کلمات محاسبهشده توسط ماتریس توجه، و اتلاف ترجمه را بهکار میگیرد تا یک نمونهی هدف هماورد بسازد.

در مرحلهی دفاعی، نمونهی مرجع هماورد بهعنوان ورودی مدل ترانسفورمر عمل میکند تا اتلاف ترجمه محاسبه شود. سپس، الگوریتم AdvGen از همان روش بالا استفاده میکند تا یک نمونهی هدف هماورد از ورودی هدف تولید کند.
در نهایت، جملهی هماورد دوباره به ترانسفورمر تغذیه و میزان اتلاف مقاومبودن با استفاده از نمونهی مرجع هماورد، نمونهی ورودی هدف هماورد، و جملهی هدف محاسبه میشود. اگر این تغییرات به اتلاف قابلتوجهی منجر شده باشد، اتلاف به حداقل میرسد تا زمانی که مدل با تغییرات مشابهی مواجه میشود این اشتباهات را تکرار نکند. از سوی دیگر، اگر تغییرات باعث اتلاف زیادی نشده باشد، هیچ اتفاقی نخواهد افتاد که نشان میدهد مدل قادر به تحمل این میزان از تغییرات هست.
عملکرد مدل ترجمه ماشینی نورونی مقاوم
ما اثربخشی رویکردمان را با اعمال آن بر معیارهای ترجمهی استاندارد چینی به انگلیسی و انگلیسی به آلمانی نشان میدهیم. بعد از اعمال، بهترتیب بهبودی معادل ۲.۸ و ۱.۶ امتیاز جایگزین ارزشیابی دوزبانه[12] در مقایسه با مدل ترانسفورمر رقابتی بهدست آمد تا عملکرد پیشرفتهی جدیدی داشته باشیم.
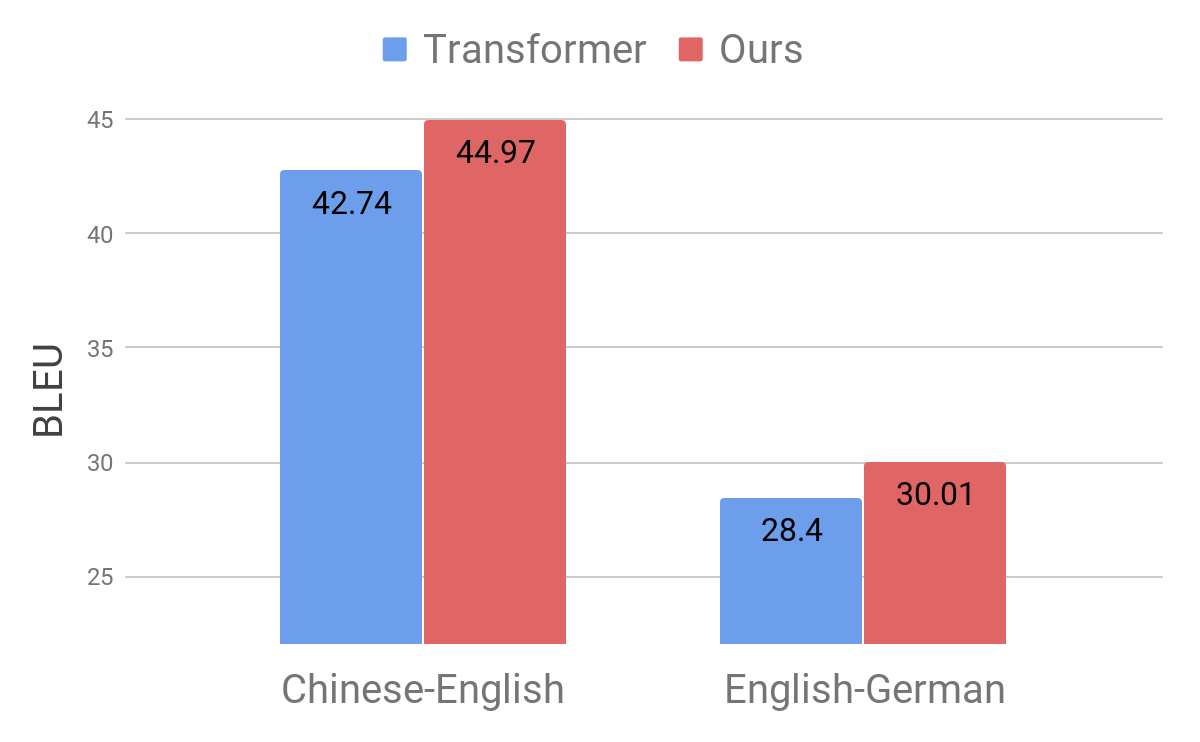
مقایسهی مدل ترانسفورمر (Vaswani و همکاران، ۲۰۱۷) در معیارهای استاندارد.
سپس، مدل خود را با استفاده از یک مجموعه دادهی متداخل (نویز)، که با رویهای مشابه آنچه برای AdvGen توضیح داده شد تولید شده است، ارزشیابی کردیم. یک مجموعه دادهی ورودی پاک، مانند آنچه برای معیارهای ترجمهی استاندارد استفاده شد، انتخاب و جایگزینهای مشابه کلمات را بهصورت تصادفی انتخاب کردیم. نتایج نشان داد که مدل ما در مقایسه با سایر مدلهای فعلی مقاومتر است.
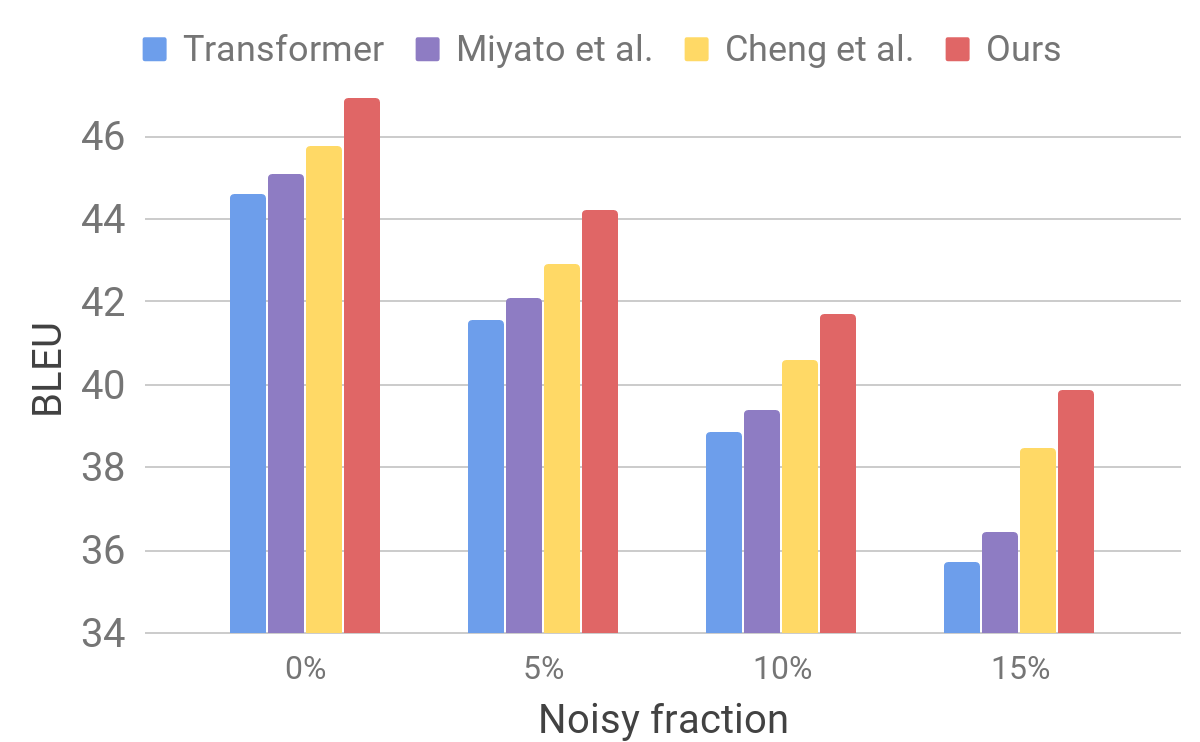
مقایسهی ترانسفورمر (Miyao و همکاران، Cheng و همکاران) در ورودیهای مصنوعی تداخلی (نویز).
نتایج نشان میدهد که روش ترجمه ماشینی نورونی مقاوم قادر است تغییرات کوچک در جملهی ورودی را تحمل کند و عملکرد تعمیم را بهبود ببخشد. این مدل بهتر از مدلهای ترجمهی رقابتی عمل میکند و در مورد معیارهای استاندارد به عملکردی پیشرفته دست یافته است. امیدواریم مدل ترجمه ما سنگ بنای قدرتمندی برای بهبود بسیاری از فعالیتهای پاییندست، بهخصوص آنهایی که نسبت به ورودی ترجمهی ناقص حساس هستند یا آن را تحمل نمیکنند، باشد.
تقدیر و تشکر
این پژوهش توسط یونگ چنگ، لو جیانگ، و وولفگانگ ماخری انجام شد. از گروه رهبری، اندرو مور و جولیا (ونلی) ژو تشکر ویژه داریم.
[1] Neural Machine Translation
[2] Transformer
[3] under-translation جاانداختن برخی کلمات یا مفاهیم در ترجمه
[4] over-translation اضافه کردن مواردی چون پانویسهای اضافی یا تکرار یک عبارت به شکلی دیگر و مانند آن
[5] mistranslation
[6] سخنگوی کمیتهی تحقیق اعلام کرد که اگر شهود فراخواندهشده همچنان از شهادت خودداری کنند، او به دادگاه احضار خواهد شد.
[7] کمیتهی تحقیق اعلام کرد که اگر شهودی که دعوت شدهاند همچنان از شهادت خودداری کنند، او به دست عدالت سپرده خواهد شد.
[8] Robust Neural Machine Translation with Doubly Adversarial Inputs
[9] adversarial
[10] Adversarial Generation
[11] Generative Adversarial Networks
[12] Bilingual Evaluation Understudy or BLEU




